這個爬蟲是的架構會是一個主副程式
這次爬了三個網站(pchome,momo,shopee),為了方便新增和維護每個網站的爬蟲,所以一個網站一個py檔
主程式的部分是去call副程式寫好的爬蟲,所以主程式這邊就是把所有資源的結果拿出來後再整理排序由小到大
一開始先從pchome的網站,先觀察他的搜尋時和中間有空格時的處理方式

所以這時我先做輸入的部分,當輸入有空格時就做url encode
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
import urllib.parse
# ==============空格處理 start=========
key2 = key.split(' ')
key2_length = len(key2)
if key2_length > 0:
key = urllib.parse.quote(key) # url encode
# ==============空格處理 end===========
以空格做字串分割,檢查有分割到的話才去取代key
接下再觀察pchome是如何產生資料,首先我先隨便搜尋來看網頁的原始碼
發現他的資料似乎是投射到頁面上的,也就是可能有前後端分離,所以這時我去看當下的network,發現下圖
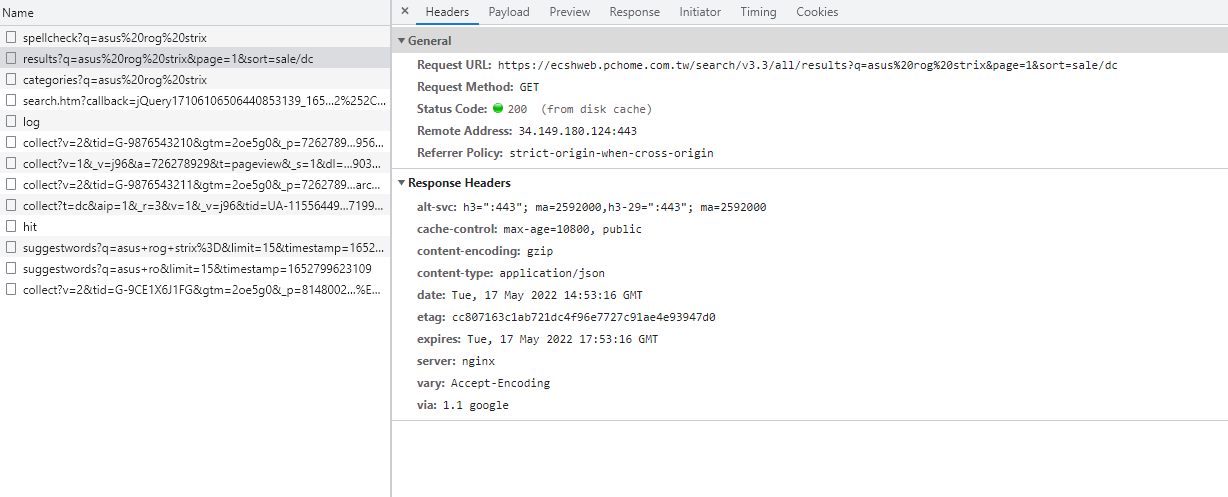
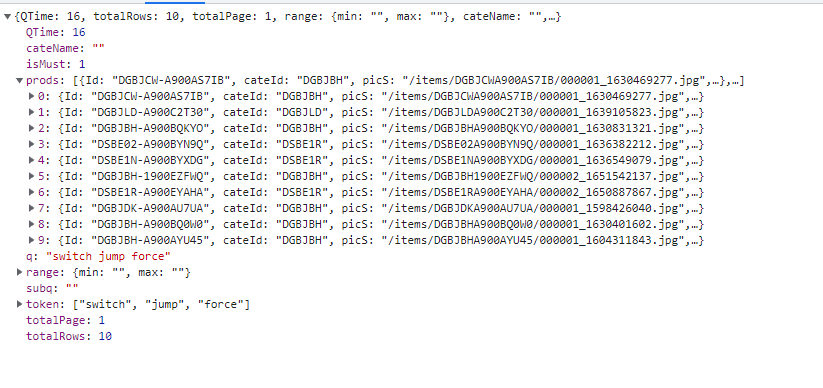
所以接下來我就透過這個網址就可以拿到資料,類似打api的概念,以下是爬取的程式碼
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import lxml
import pandas as pd
def get_prods(key):
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
url = "https://ecshweb.pchome.com.tw/search/v3.3/all/results?q=" + \
key+"&page=1&sort=sale/dc"
# 靜態爬取
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
content = soup.find('p').text
content2 = eval(content) # 把字串型list轉成list
length = len(content2)
以上程式碼解說:
1 寫成def以便主程式去call
2 帶header是為了模仿一般使用者header來提高爬取成功率
3 爬回來的內容直接用eval()去轉成list
# 沒有資料的話就會退出
if length == 0:
return ["沒有此商品"]
# ===========整理資料拿出金額最小的 start===========
df = pd.DataFrame(content2['prods'][0:10]) #取出前10筆資料
content3 = df.min().to_dict() # 找出最小的價格的商品資料轉字典
# ===========整理資料拿出金額最小的 end=============
# 放商品名稱和和價格
result = {
"平台": "PCHOME",
"商品名稱": content3['name'],
"價格": int(content3['price'])
}
return result
以上程式碼解說:
1 檢查length有沒有長度,沒有的話判定沒有搜到東西,就直接退出
2 因為他的資料都放在prods欄位裡面,再取前10筆的資料,再把資料丟到dataframe裡面
3 使用 dataframe的min函數再透過to_dict()轉成字典
4 最後在整理資料回傳給主程式
在pchome.py找ROG Zephyrus G15 筆電的結果:

===========================================================================
接下來是蝦皮的過程
這邊觀察的過程也是先看搜尋時的空格處理方式,發現他也是用url encode

所以這邊的字串處裡也是用跟pchome一樣的處理方式
再去觀察他產生資料的方式,發現也是跟pchome一樣有前後端分離,所以只要找出搜尋完吐到前端的後端api,之後爬取的目標一樣打這支api,下圖是蝦皮的network
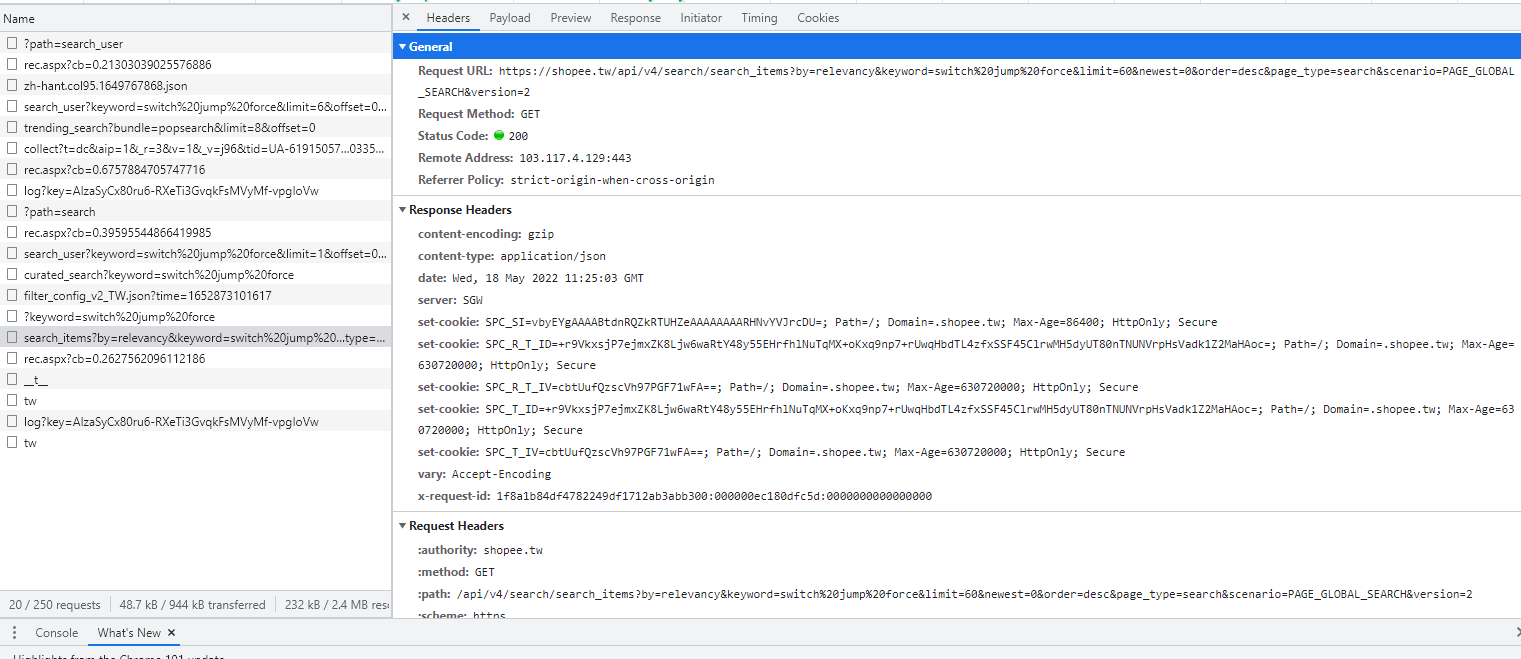
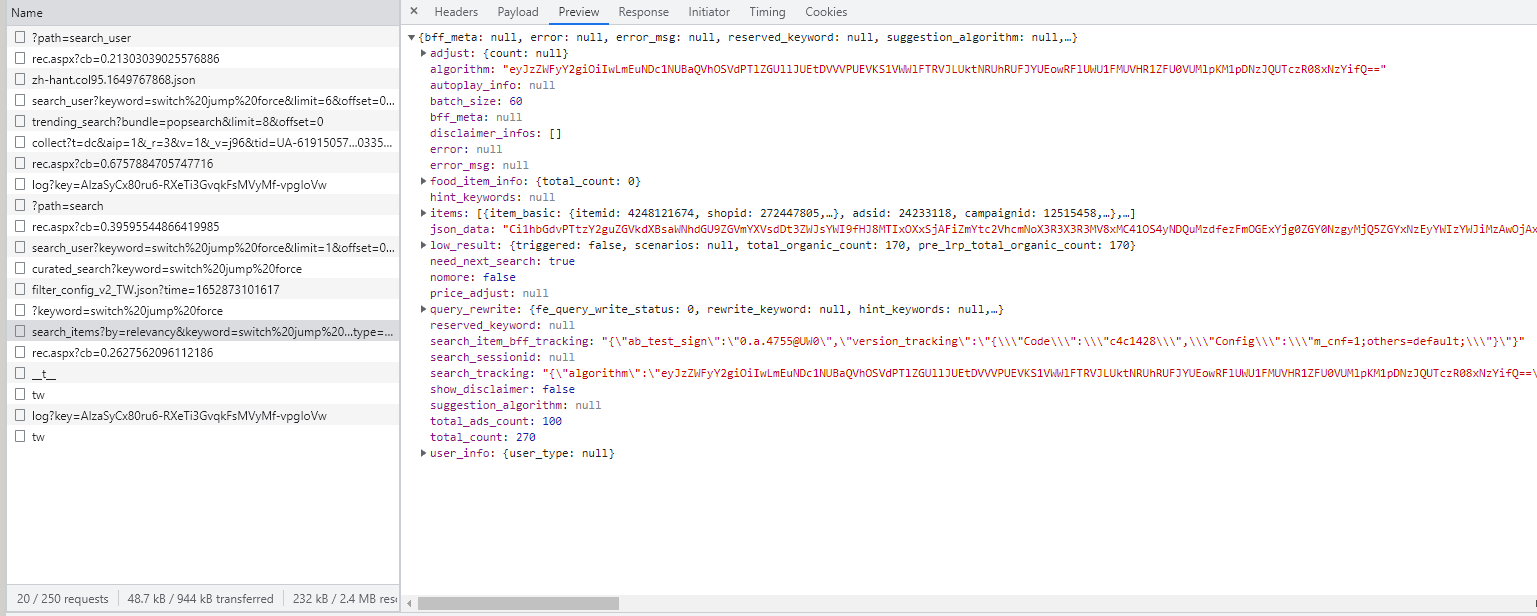
接下來我就透過這個網址就可以拿到資料,類似打api的概念,以下是爬取的程式碼
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-import json
import requests
from bs4 import BeautifulSoup
import lxml
import pandas as pd
def get_prods(key):
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
url = "https://shopee.tw/api/v4/search/search_items?
by=relevancy&keyword="+key + \
"&limit=10&newest=0&order=asc&page_type=search&scenario=PAGE_GLOBAL_SEARCH&version=2"
# 靜態爬取
result = []
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
content = soup.find('p').text # 商品都在裡面
content2 = json.loads(content)
以上程式碼解說:
1寫成def以便主程式call
2帶header來提高爬取成功率
3爬回來的結果是用json編譯,所以用json.loads去解碼
length = len(content2['items'])
if length == 0:
return ["沒有此商品"]
# ==============整理爬下來的資料 start===========
result = []
for row in content2['items']:
item_name = row['item_basic']['name'] # 商品名子
item_price = row['item_basic']['price'] # 商品直購價
item_price_min = row['item_basic']['price_min'] # 商品最低價格
item_price_max = row['item_basic']['price_max'] # 商品最高價格
x = 0
for d in key2:
if d in item_name:
x += 1
if x == key2_length:
result.append({
"name": item_name,
"price": item_price,
"price_min": item_price_min,
"price_max": item_price_max,
})
# ==============整理爬下來的資料 end===========
if len(result)==0:
return ["沒有此商品"]
# ===========找出最低價格的key值 start===========
df = pd.DataFrame(result)
min_price = df['price'].min()
for key, value in df['price'].items():
if value == min_price:
min_key = key
break
# ===========找出最低價格的key值 end============
# ===========整理價格 start=====================
price = min_price/100000
# ===========整理價格 end=======================
finish_result = {
"平台": "SHOPEE",
"商品名稱": df['name'][min_key],
"價格": int(price)
}
return finish_result
以上程式碼解說:
1 檢查length 有沒有長度,沒有的話判定沒有搜到東西,就直接退出
2 因為商品都放在items欄位,以這個去跑回圈
2-1商品在放到變數之前先檢查key裡的字有沒有都在商品的名字裡
2-2 都有的話就新增資料到list
3 檢查list有沒有長度,沒有的話回傳[“沒有此商品”]
4 把list放到DataFrame裡面再用df[‘price’].min()找出最低價格,再用迴圈找出這最低價格的key
5 用這個key拿出相對應的名字和價格回傳給主程式
在shopee.py找ROG Zephyrus G15 筆電的結果

===========================================================================
接下來是momo的過程
這邊觀察的過程也是先看搜尋時的空格處理方式,發現momo也是跟前面一樣用url encode,所以空格處理方就跟前面一樣
但爬取momo時發現他的情況跟前面兩個不太一樣,
1 先看他的的原始碼放資料的地方發現他是有做承接的部分,再從network看似乎都是js在傳遞資料
2 用他的pc網址來爬取但回傳回來的沒有商品
3 用手機板網址就可以了爬到搜尋到的內容,之後就沒再拆他的api
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
import sys
import json
import requests
from bs4 import BeautifulSoup
import lxml
import pandas as pd
def get_prods(key):
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
# 拿mobile版型的
url = "https://m.momoshop.com.tw/search.momo?_advFirst=N&_advCp=N&curPage=1&searchType=&cateLevel=-1&ent=k&searchKeyword=" + \
key+"&_advThreeHours=N&_isFuzzy=0&_imgSH=fourCardType"
# 靜態爬取
result = []
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
content = soup.find_all('ul') # 商品都在裡面
以上程式碼解說:
1 寫成def以便主程式call
2 帶header提高爬取成功率
3 商品都放在ul裡面,所以先找他
下面的程式碼跑回圈找每個商品資料
for row in content:
if row.find('div', class_='prdInfoWrap'):
result_temp = {}
prod = row.find_all('div', class_='prdInfoWrap')
for row2 in prod:
prdName = row2.find('h3').text
prdName2 = prdName.split('\r\n') # 商品名子
if len(prdName2) == 2:
prdName3 = prdName2[1].strip() # 商品名子去左右空白
if key2[1] in prdName3:
# 商品價格
price = row2.find('b', class_='price').text
result_temp = {
"name": prdName3,
"price": price,
}
result.append(result_temp)
length = len(result)
if length == 0:
return ["沒有此商品"]
df = pd.DataFrame(result)
min_price = df.min()
finish_result = {
"平台": "MOMO",
"商品名稱": min_price[0],
"價格": int(min_price[1])
}
return finish_result
以上程式碼解說:
1 檢查div的class是prdInfoWrap有值時在進判斷
1-1 對div的class是prdInfoWrap進行find_all,因為這個似乎只有一組,本來是用find去找但是後來發現他似乎都搞在一起
1-2 接下來就對這個div進行迴圈,從h3找出名字,在對這個名字進行空格處理
1-3 先對名字已‘\r\n’做字串分割,如果分出來的有兩個元素再進行後續處理,沒分出的話可能就是遇到的不是商品的內容
1-4 分到後再去商品的左右空白
1-5 檢查 輸入的第二個字有沒有在商品名字裡面,有的話再把商品名字和價格放到list變數
2 檢查list變數有沒有長度,沒有就回傳[“沒有此商品”]
3 把list變數放到dataframe裡面,在用min()找到最低價格
4 最後回傳商品名字和價格給主程式
在momo.py找 ROG Zephyrus G15 筆電

接下來是主程式的部分
import pchome import momo import shopee import pandas as pd
會先引入前面寫好的三個py檔
key = input("請輸入要找的商品:")
finsih_result = []
# =======爬momo的商品 start===============
result_momo = momo.get_prods(key)
if len(result_momo) > 1:
finsih_result.append(result_momo)
# =======爬momo的商品 end=================
# =======爬pchome的商品 start=============
result_pchome = pchome.get_prods(key)
if len(result_pchome) > 1:
finsih_result.append(result_pchome)
# =======爬pchome的商品 end===============
# =======爬shopee的商品 start=============
result_shopee = shopee.get_prods(key)
if len(result_shopee) > 1:
finsih_result.append(result_shopee)
# =======爬shopee的商品 end===============
df = pd.DataFrame(finsih_result)
finish = df.sort_values(by=['價格']) # 價格小到大
finish.to_csv("比價.csv")
print("end")
以上程式碼解說:
1 輸入要找的商品名字
2 call 各個py裡的get_prods function,如果回傳的長度沒有大於1的話就代表該平台沒有此商品,有的話就新增到finsih_result
3 把finsih_result放到DataFrame裡面
4 用DataFrame的sort_values做排序,以價格欄位來排小到大
5 輸出csv
最後結果:

在這邊感謝張維元老師開的資料科學教戰營:社群共學讓我對往資料工程師有了方向,也學習到DataFrame的使用,雖然還有學到斷詞處理但目前先實作這個比價爬蟲
資料科學工作日常:url