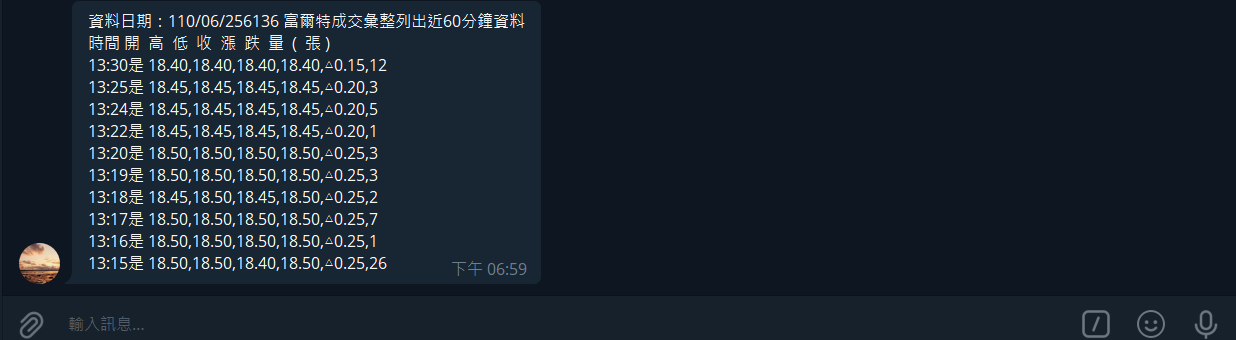
這個爬蟲去yahoo股市爬一間新店的軟體公司的成交彙整資料
把成交彙整的表格裡的資料都拿出來
一開始我先去yahoo股市的頁面看要爬的目標在哪裡
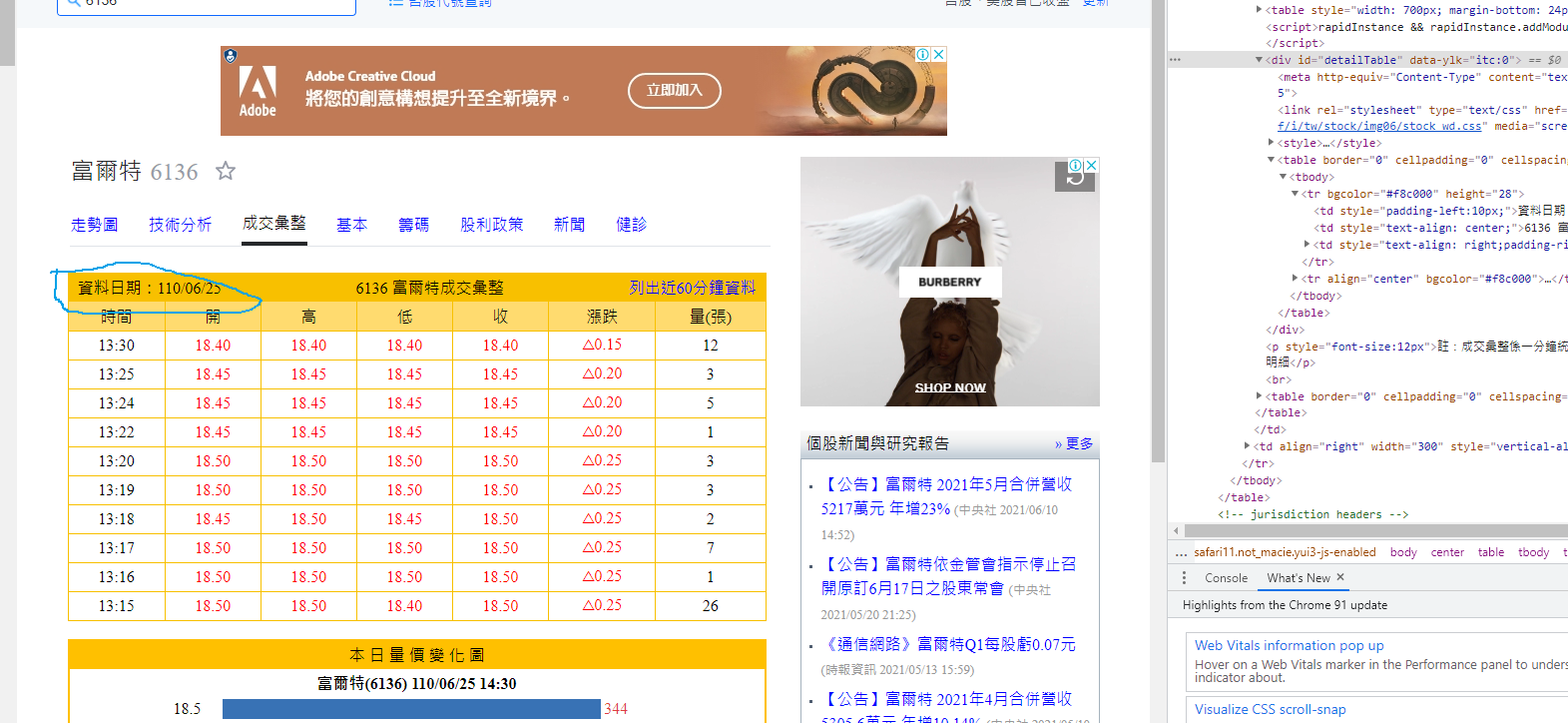
按F12再點資料日期發現他的區塊id,我的第一步就先把他這區域的程式碼拿下來
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
import sys
import json
import requests
from bs4 import BeautifulSoup
import lxml
import pandas as pd
import numpy as np
import codecs
#---------------------------爬取股票資料 start---------------------
#奇摩股票網址爬富爾特 6136
res = requests.get("https://tw.stock.yahoo.com/q/ts?s=6136")
res.encoding='big5'
soup=BeautifulSoup(res.text,'lxml')
# 鎖定id=detailTable的範圍,這是成交彙整區塊
#再從table->tr拿取其中的文字和內容
soup2=soup.find_all('div',id="detailTable")
result_text=[]
x=1
x1=""
for d in soup2:
try:
result=d.find('table')
print(result)
except:
print("有異常")
#---------------------------爬取股票資料 start----------------------
先把div id=”detailTable” 的資料拿下來後,再從中拿出table的程式碼
結果:
再把這些程式碼貼到vscode整理,以下是貼到vscode的畫面
從上面發現我要的資料都在tr裡面,所以在往下塞選把tr拿出來
for d in soup2:
try:
result=d.find('table')
result_1=result.find_all('tr')
for item in result_1:
rs=item.text #拿tr裡面的文字
print(item.text)
result_text.append(rs)
except:
print("有異常")
拿到每一筆tr的內容後先存到result_text陣列裡,以便後面資料處理用
下面是每一筆tr的內容:
資料處理的部分先處理標頭文字
# ---------------------------處理標頭文字 start-------------------- sendmessage='' title2='' for i in range(0,len(title[0])): if i==1 or i==0: title2+=title[0][i] continue title2+=' '+title[0][i]+' ' if i==len(title[0])-1: title2+=')' sendmessage=result_text[0]+"\n"+title2+"\n" # ---------------------------處理標頭文字 end-----------------------
迴圈跑完後新增到要傳送到tgbot的字串變數
結果:

處理每一條資料,因為這時候還是黏在一起的
# ---------------------------整理每一條資料 start------------------
i=1 #計數
k=1
result_string=''
sting_list=[]
for item in result_text:
if i>=4:
for item2 in item: #整理每一條數字
result_string=result_string+item2
if k%5==0: #當符合一組的時候就新增陣列,在重置字串變數
# print(result_string)
sting_list.append(result_string)
result_string=''
if k==len(item):
# print("長度"+str(len(item))+"最後:")
# print(result_string)
sting_list.append(result_string)
result_string=''
# sting_list.append(result_string)
# result_string=''
k+=1
k=1
i+=1
# print(sting_list)
#陣列分割,每七個一組形成二微陣列
# ---------------------------整理每一條資料 end---------------------
因為每一組數字和時間剛好都是5位,所以在新增陣列的時候是串好5個字元再新增
新增完後字串連接用的變數初始化為空字串,下一組串接時就不會有其他組的字元
資料組好後在把陣列切成跟頁面上的表格一樣
#把一微陣列分割成二維,看要分成幾個元素一個陣列 def divide_chunks(t, n): # looping till length t for i in range(0, len(t), n): yield t[i:i + n]
以上這個作法是上網找到 參考資料
把要處理的陣列放在第一個,幾份為一列放在第二個
套過上面的function幫我把想要的二維陣列切出來
finish=list(divide_chunks(sting_list,7))
下面做最後的整理要廚到tgbot那邊得字串
# ------------------------處理每一個時段數據 start------------------ finish_string='' p=1 #每一排的計數 b=1 #每一圈的計數 for f1 in finish: for f2 in f1: if p==1: finish_string+=f2+"是 " p+=1 continue if p==len(f1): finish_string+=f2 break finish_string+=f2+"," p+=1 sendmessage+=finish_string+'\n' #新增要傳到tgbot的字串變數 if b==10: #10以後的不拿 break p=1 #重置計數 finish_string='' #重置字串串接變數 b+=1 # ------------------------處理每一個時段數據 end-------------------
先整理每一行資料,迴圈出來後加上換行符號後再串接字串
會只停在第10圈是因為線面長條圖不拿
def tgbot(text_string): #這邊放從tgfather拿到的token bot_api_key = 'tgbot的key'; url = 'https://api.telegram.org/bot'+bot_api_key+'/sendMessage?chat_id= tgbot的id &text='+text_string+'&parse_mode=html' s = requests.Session() r1 = s.get(url) result2=json.loads(r1.text) re1=[] if result2['ok']==True: re1=[1] return re1 elif result2['ok']==False: re1=[0,result2['error_code']] return re1
有另外寫個function去接tgbot的api
api網址的組成 https://api.telegram.org/bot+tgbot的key+’/sendMessage?chat_id= tgbot的id &text=’+text_string+’&parse_mode=html’
這邊是用requests.Session() 把字串傳進去,api回傳的結果用json.loads來解析,傳失敗的話會回傳錯誤訊息來查看
下面是使用tgbot的程式碼
tg_get=tgbot(sendmessage)
if tg_get[0]==1:
print('成功')
elif tg_get[0]==0:
print(tg_get[1])
結果: