要把一個網頁上的圖片載下來的話,可以用爬蟲把圖片網址篩選出來後
再把圖片載下來,以下是爬豆瓣首頁上的圖片
程式分兩大部分:篩選圖片網址和下載圖片
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import lxml
import os
from urllib import urlretrieve
import sys
r1=requests.get('https://www.douban.com/') #豆瓣網站
soup=BeautifulSoup(r1.text,'lxml')
image=soup.find_all('div')
#下面的迴圈是找圖片網址再把結果放到陣列裡
links=[]
for d in image:
if d.find('img'): #再從div找img裡面的src
result=d.find('img')['src']
print result
links.append(result)
註解: 先抓出元素div的程式碼,再從中找出元素img裡的src也是圖片網址,再把每一筆結果放到陣列裡
#下面的迴圈是把剛存進陣列裡的結果做下載的動作
x=1
for link in links:
local = os.path.join('D:\py\musicplayer\webcrawler save\image\%s.jpg' % x)
urlretrieve(link,local) #link是下載的網址 local是儲存圖片的檔案位址
x+=1
註解: 把剛才放到陣列裡的網址用for迴圈把結果叫出來
os.path.join 這行是存檔的位置
urlretrieve(link,local) link是網址,local是存檔的路徑
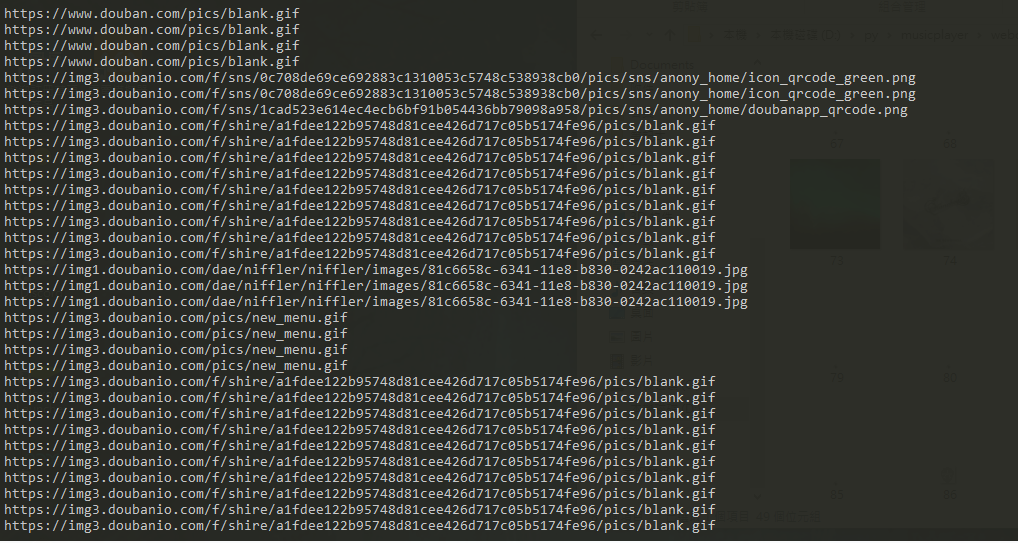
結果: