當你要爬資料之前
首先你要先找到你要的資料在目標網站裡的哪個位置
找到後再開始思考你要怎麼篩選html程式碼才會抓到你要的data
我的經驗是有時不能直接搜他包覆的html code,例如他是span、a之類的
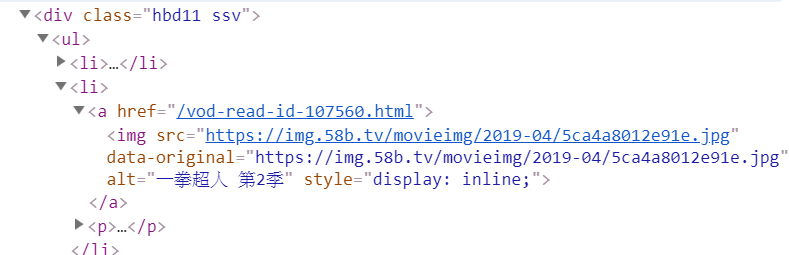
從上圖來看的話要從他的外層再進入他的內部
或者透過他的class去做篩選,結果就會局限在這個小區域裡,也比較快找到
如果你要使用這個網站的搜尋的話
你要先找到他的規則,找到後並加以分析就可以使用他規則
這樣的作法很像python的 import或是php的 require、include的概念化
最後如果要把爬的結果存起來請先看看你的量和完整性再存